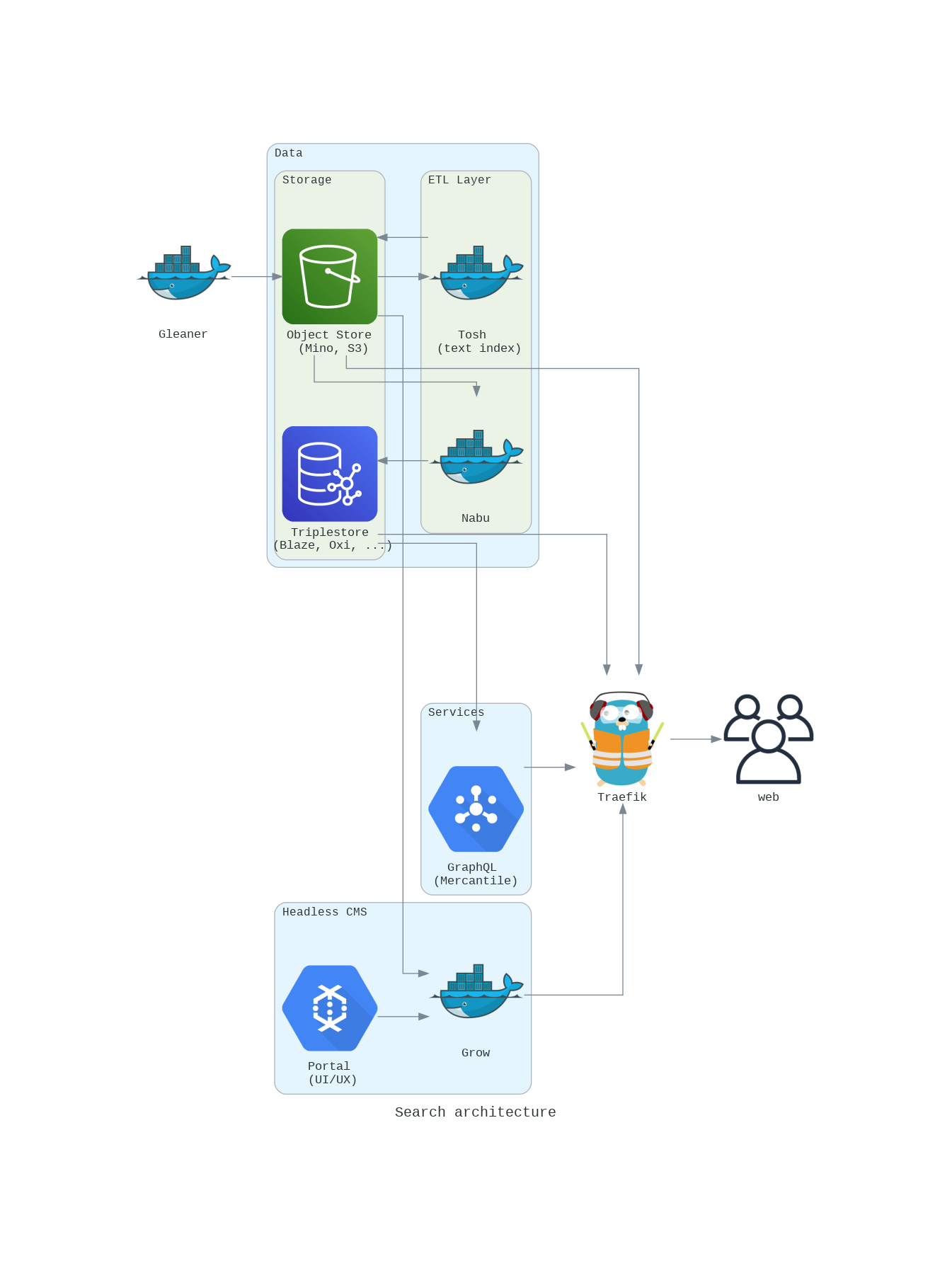
The Bigger Picture
Gleaner
Gleaner is a tool for extracting JSON-LD from web pages. You provide Gleaner a list of sites to index and it will access and retrieve pages based on the sitemap.xml of the domain(s). Gleaner can then check for well formed and valid structure in documents and process the JSON-LD data graphs into a form usable to drive a search interface. It is part of a bigger picture.
Overview
The architecture defines a workflow for objects, a "digital object chain". Here, the digital object (DO) is the data graph such as the JSON-LD package in a landing page.
The chain is the life cycle connecting; authoring, publishing, aggregation, indexing and searching/interfaces.
Authoring & Publishing
Schema alignment work aligns existing metadata formats to schema.org (plus other vocabulary/contexts) serialized as JSON-LD. Publishers are engaged on approaches to using robots.txt, sitemap.xml and their existing web stack to expose these resources. This same approach is also used by Google Dataset Search and allows the resources to be leveraged by them and an emerging community of potential users and projects like OIH.
Aggregate, Index and Use
* Data graphs are aggregated by Gleaner and formed into a RDF graph that is loaded into a triplestore. Graphs can optionally be checked and validated.
* The SPARQL endpoint can be open and/or exposed by Mercantile via GraphQL.
* Web based user interfaces for this approach exist and are served along with access to the metadata objects via GROW. The approach is JAMSTACK based so many clients and client frameworks can leverage the exposed APIs.
This full stack is assembled into Docker/Open Container Initiative containers and can be deployed to orchestration environments like Docker Swarm, commercial cloud environments or even single computers.